gRPC and the Displacement of Rest-Based Apis






Introduction
"gRPC is a modern, open source remote procedure call (RPC) framework that can run anywhere. It enables client and server applications to communicate transparently, and makes it easier to build connected systems." Some frequently asked questions are answered here. This article explains a little bit about gRPC, why we chose it, how we implement it, and some basic tips and lessons we've learnt along the way.
At Sajari we chose gRPC over JSON/HTTP RESTful APIs (referred to as REST from here-on-in) for multiple reasons:
- JSON encoding/decoding/transmission was a significant portion of latency profiling
- We found the Swagger and Open API Initiative specifications deficient for our purposes
- When managing many microservices, REST was too loosely defined and promoted mistakes
- HTTP2 by default
The above can be loosely summarised as speed, capabilities and more robust API definition. Below is an outline of each of these and why they are important to us. We believe gRPC will end up replacing many REST based services as the advantages are too many once the initial concepts are grasped.
gRPC is very fast
gRPC is faster than REST. Others have documented this, but in a nutshell, it runs on HTTP2 by default (see a comparison by Brad Fitz) and when using Google's protocol buffers (you don't have to) for encoding, the information comes on an off the wire much faster than JSON. There's also bidirectional streaming, header compression, cancellation propagation and more.
Our backend services are very low-level optimised, to the point where using JSON encoding was actually a noticeable portion of the latency when profiling. Other applications that don't care about speed might not worry about this, but for a distributed and data heavy application this actually makes a noticeable difference.
gRPC is robust
RPC allows a connection to be maintained between two machines for the purpose of executing functions remotely. Where as in REST calls the request and response are totally de-coupled: you can send anything you like and hopefully the other end understands what to do with it. RPC is the opposite, it effectively defines a relationship between two systems and enforces strict rules which govern communication between them. That can be pretty annoying at first, as you need to update both the server and the client to keep things working when you make changes, but after a while that actually becomes invaluable as it prevents mistakes. This is particularly evident when your backend is comprised of many microservices, which is the case for us.
SDK generation is easy
One of our key aims was to be able to generate SDKs across many languages in a way that would scale well with changes. We spent a lot of time on Swagger and Open API based document/SDK generation for REST/JSON APIs and for several reasons we ended up choosing gRPC instead. The key reasons we didn't like Swagger were:
- Poor support for nested structures
- No support for associative arrays
- Non-ideomatic SDK generation, particularly JavaScript
- Felt more geared towards objects, search API requirements are quite different
gRPC generates pretty nice basic SDK skeletons. It also supports all the functionality we needed like nesting, so that was a great start.
Downsides of gRPC
The main reasons (for us) to avoid gRPC were:
- Poor browser support for gRPC
- Extensions required for PHP, etc
- App Engine (Classic) doesn't properly support gRPC
Much of what we do is browser based JavaScript, so browser based gRPC as a non-starter was relatively annoying, but we managed to resolve this relatively simply. In order to minimise the workflow disruption, we created an HTTPS service wrapper for the gRPC service itself which would allow JSON encoded messages to be sent via HTTPS instead of gRPC. The wrapper does a conversion to gRPC, which then continues on as normal in our internal systems. Proto3 supports JSON mapping, so most of the heavy lifting is done. We originally wanted to support proto messages directly in the browser, but hit some snags with Internet Explorer (surprise!) so we had to fall back to JSON. We're aware of others using flatbuffers in the browser, but we didn't want to manage an additional encoding scheme with its own JavaScript nuiances.
The PHP extension issue is also annoying as while it works great, many people don't have access to extensions on their host. On balance we think this is OK and in any case the same techniques we used for JavaScript can be repeated.
We currently use App Engine for all of our external-facing APIs (though this is going to change soon). Unfortunately App Engine requires a custom dialer for gRPC (and can't keep connections open between requests. In general it's just not optimal, but in reality not a problem for us.
Backend compatibility
Another key advantage is we wanted to use gRPC internally for our backend service communication, so it was nice to have the same technology across both internal and external APIs.
Other advantages of gRPC
gRPC supports useful additions like standard error responses and meta data. Meta data is particularly useful for us, as it's possible to embed things like data access details, auth, SDK version info and other useful information that cascades through many backend services.
gRPC is designed to support mobile SDKs for Android and iOS. Keeping a communication pipe open between a phone app and backend service is very useful for creating low latency mobile applications. Sajari is part database, part search engine, so this is even more valuable for us.
Tracing is also built in, which is extremely useful. Because requests can be tracked using the same context through multiple services, it's possible to cancel requests on different systems and or trace them to see what is causing delays, etc. Below is an example of some tracing built into our autocomplete service.
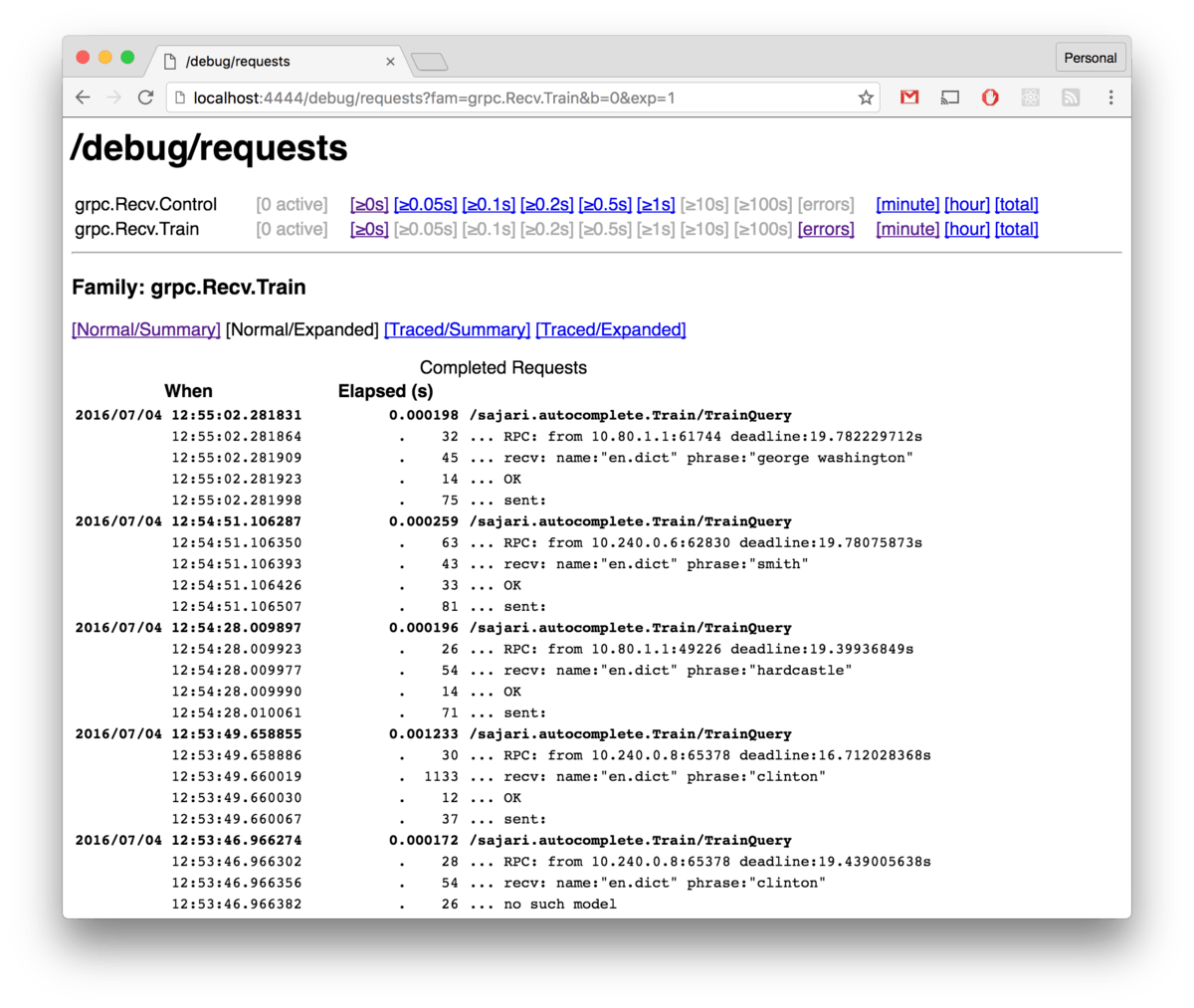
Above is a very simple service, so the tracing doesn't tell us too much, but this is totally up to the developer, so additional tracing is a piece of cake to add. If you use Google Cloud tracing is even better, cloud logging shows when traces are available, so you can click on a sample set of requests in your log to trace them:
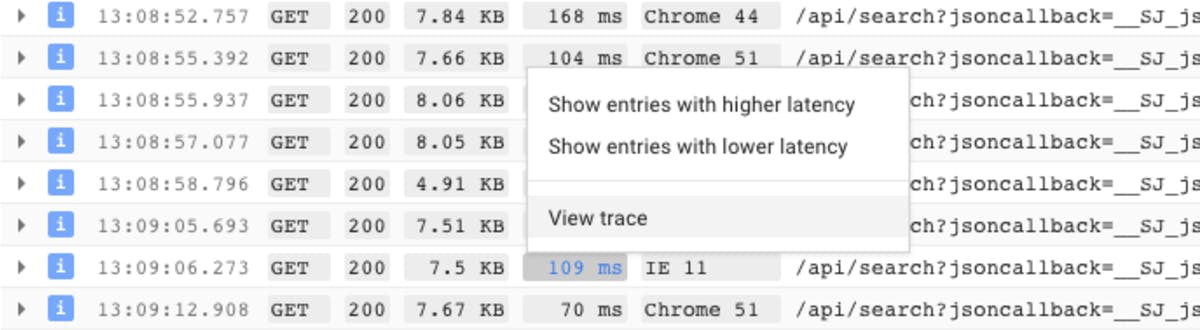
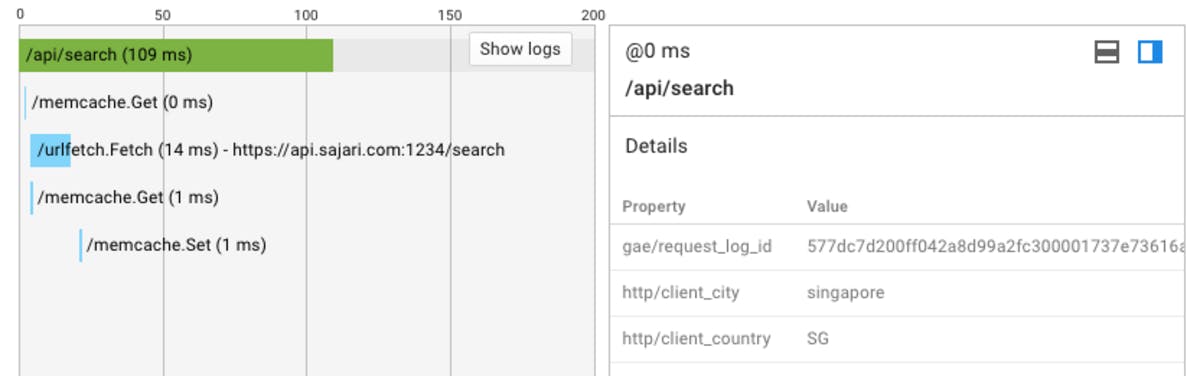
Google cloud then shows the full trace. Conveniently it has stitched multiple traces together for you so you can see exactly what is happening within your requests as they traverse multiple systems. Below is an example from one of our legacy systems.
Adding a trace in Go is pretty simple, it begins with importing the "trace" pkg:
You can then hook into the context and add your trace as per the example below, which comes from the below documented autocomplete service. In gRPC, the context is the unique identifier for the request, which is used to follow requests around as they traverse multiple systems.
Tips and tricks we've learnt
Autogenerate clients and servers
We write backend code almost exclusively with Go, which has great support for both protocol buffers and gRPC (more info). Service and data definitions are extremely simple and the client and server code can both be autogenerated directly from these definitions. From a workflow perspective, the proto is the source of truth, we hardly ever look at the Go code generated as the proto is much simpler and defines everything you need to know. When we update the proto we then run a script to re-generate all our Go code. Anything that doesn't build after re-generation needs to be amended to match the new changes. This makes it very difficult to ship two services with incompatible APIs.
A partial service definition looks like the following (note the actual full service is roughly 3 times larger, which in total generates about 500 lines of Go code):
Keep definitions separate from code
Initially we kept proto definitions in their respective repositories, but this caused problems. Anyone familiar with Go would understand why, but essentially this made it difficult to ensure proto definitions and generated code were up to date. Additionally a common requirement was to have different people working on different services, separation allows access to the full API interface without needing access to the actual service code behind it. So we ended up changing our original strategy to instead use a separate repo for all our proto definitions. This repo also includes a shell script to regenerate all of the client and server code.
Below is part of a shell script we use to generate all our Go code from the proto definition files. The protoccommand has the additional grpc:go plugin, which creates our Go code for us.
The last thing to mention with keeping the definitions separate is they are completely language agnostic, so they don't belong in the service code repo. You may have contributors working with different languages and the proto becomes the glue. Clients and services generated in different languages from these definitions will happily communicate with each other. Tensorflow is one large open source project that uses gRPC to connect services.
Google App Engine (Go)
Although you can't use App Engine (Classic) to host gRPC servers, you can run gRPC clients. App Engine uses a specialised package for creating network connections (see appengine/socket) so a bit more work is required to establish the initial connection. Unfortunately the socket pkg tends to be very unreliable when running in the local dev server (as of go version go1.6.1 (appengine-1.9.38) darwin/amd64) so we also check the environment before overriding the default dialer.
Use protocol buffers
gRPC allows you to specify your own encoding, so why choose protocol buffers? Internally we use our own binary encoding libraries for data storage and traversal, we mainly do this because they are several orders of magnitude faster than protocol buffers and support partial reads, atomic increments, zero-copy reads, etc. But we still still prefer protocol buffers for service communication as the technology is incredibly well thought out, easy to follow and a widely known standard. In general we find you trade performance for simplicity. gRPC glues everything together for us, it's the boundary between developers and systems, so simplicity is our primary concern and protocol buffers just works.
Re-use and manage connections
gRPC is much more efficient if you re-use connections, so if you know you're going to use the same connection again, keep it open. Much like the Go HTTP handler you also need to close connections you no longer want to use. We've seen some strange issues when using a lot of connections, so we also try to avoid that getting out of control for lots of small data. gRPC supports bi-directional streaming, so take advantage.
Conclusion
gRPC is a big part of our future and we believe it will be a hugely important component for organisations embracing a microservice architecture.


