An Engineering Year in Review: Kubernetes, gRPC, and More





2016 was a massive development year for our team. This post is a quick look at some of the larger changes, why we made them, what we learnt and how these changes have set the foundation for the future.
Monolith to Services
People debate the benefits of moving to services (there are definitely downsides), but building large scale distributed systems almost forces the services route, as different components scale out in different ways and distributed state needs extra attention .
Prior to 2016 we were running on two main monolith systems, our front-end service and our search backend. The front-end handled requests, auth, configuration, crawling and other outward facing services, while the backend was our own home grown search engine, which handled the search index, language processing, machine learning, disk backups, autocomplete and much more.
Over time the complexity of the backend had unintentionally grown enormously in order to chase performance. The performance chase succeeded, but this also left an application that was difficult to work with and very difficult to distribute (a core goal). So with a mind towards the index becoming fully distributed we began rebuilding the backend into several services.
This rebuild has been a great success. We have a much cleaner codebase and have actually increased performance over our older version (more on that below). The component boundary is now very clear and scaling services is now largely fully automated. If there is one downside it's the management of multiple repos, which definitely slows development down somewhat, but it also provides great separation.
Protocol buffers over JSON
A lot of very smart people have put a lot of time into protocol buffers and it shows. At one point we were profiling our search engine code and noticed over 30% of the CPU time was spent encoding and decoding JSON. That seemed crazy, but hey everyone loves JSON...
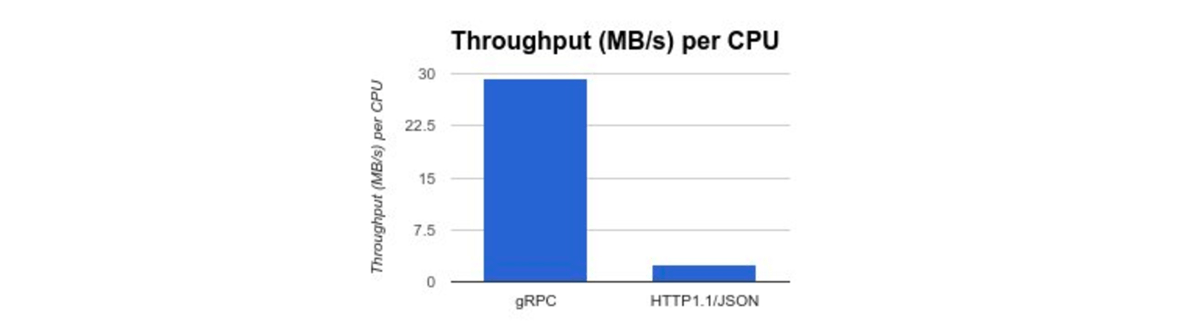
After seeing a talk on gRPC and getting some insight as to how google use stubby internally, it seemed like it might be a great fit for us (see our previous gRPC vs REST article). We spent a long time on it and we're still dealing with some aspects, but overall it's been a great move. Encoding is not dominating our CPU profiles anymore, our internal systems are coupled nicely with contextual tracing through our systems and our SDKs all use a single definition and come with HTTP2 steaming, tracing, cancellation and lots more out of the box.
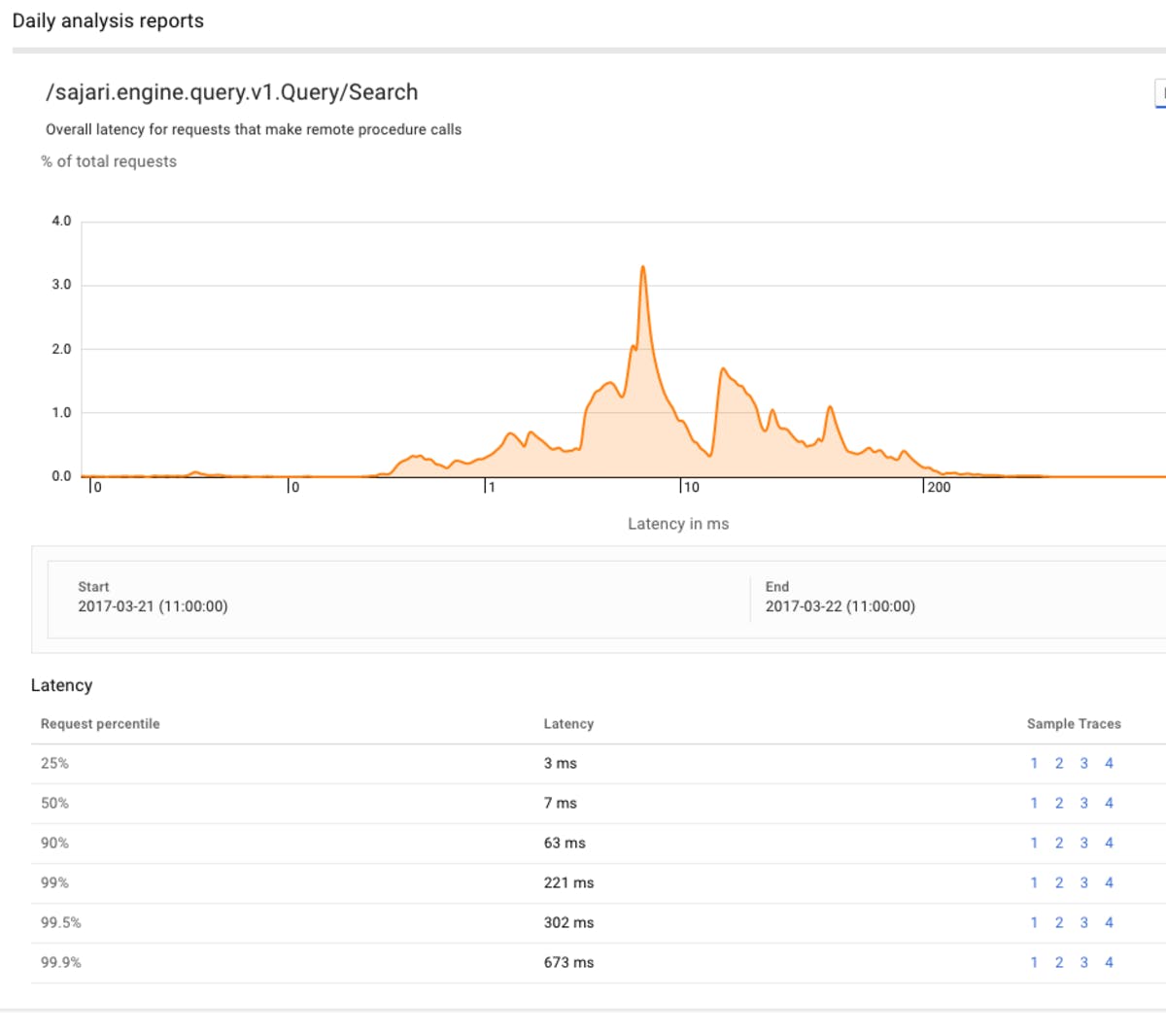
I would note here that we use our own binary encoding package for internal data representations as we can beat the throughput of Protobuf by several orders of magnitude (which also shows just how slow JSON encoding really is), so we're not suggesting you build databases with Protobuf as some people do (same goes for Flatbuffers). However Protobuf handles much more than just encoding and those added benefits make it ideal for connecting distributed systems, but always keep in mind those added features aren't free!
Mobile
gRPC allows a single connection to remain open and stream binary data bidirectionally using HTTP2. For mobile devices this is huge. It saves battery, CPU and speeds up data transfer by a) transmitting binary instead of json/xml/etc and b) it allows mobile clients to run functions directly inside our backend services.
The other benefit is that gRPC can generate mobile SDKs, so it's now easy for us to keep an up to date versioned API that works great for mobile.
Kubernetes
Seeing a talk at Google on Borg and Kubernetes was one of those "mind blown" moments that changes the way you think about everything. You can read up on some background here. We also previously wrote an introduction on why we chose Kubernetes.
Before Kubernetes we used deploy scripts and VMs, this seems pretty backwards now. Kubernetes abstracts away VMs and provides a single resource plane to deploy many services via containers. It also handles scheduling the containers and services, connecting all the DNS (using simple labels), manages scaling, load balancing and much more. Soon that single resource plane will be federated across multiple data centres in different continents.
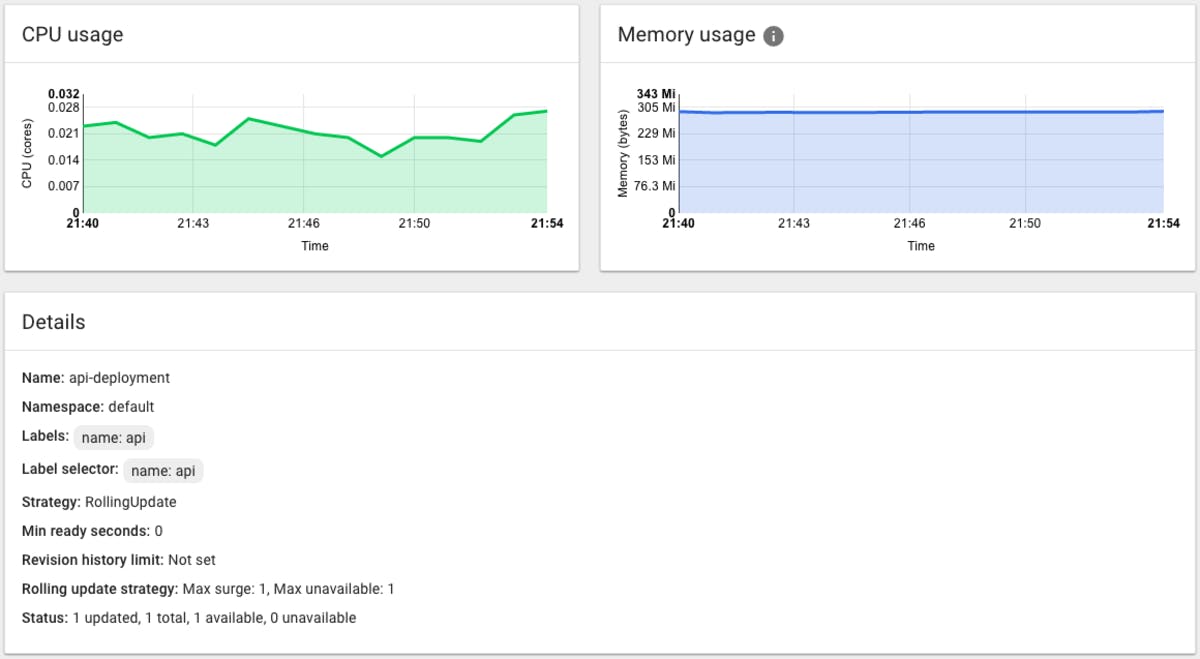
This is a sample interface console showing a service in one of our clusters. This console proxies directly into the cluster from localhost, which is incredibly useful to quickly see what is happening in the cluster. Labels are used to connect everything.
Kubernetes just makes things easy. To put things in perspective, when we first started testing we kept trying to kill containers to see what would happen, but before we could switch screens to see what happened they were already back running! Luckily Kubernetes has built in logging so it was easy to see that we did in fact kill them.
This brings a second interesting side effect of using Go based Docker containers is they can be tiny, normally less than 15MB. The majority of our services have no dependencies outside of the executable itself, which allows us to use the "scratch" Docker template, no OS, no JVM, no bloat. Consequently they can be moved around and started extremely quickly (sub second).
FROM scratch
EXPOSE 1234
COPY synd /
ENTRYPOINT ["/synd", "-listen", ":1234"]
Above shows a typical Dockerfile for one of our services, it can't get much easier.
Analysis
In the past our text analysis was baked into the engine. Firstly it didn't support all languages, secondly it did a lot of parsing with regexes and was generally a bit brittle. From the outside this didn't matter too much as we a) only dealt with English and b) things like stemming are relatively symmetric, so for most queries it didn't matter. Fast forward and we now have an amazing tokeniser that can handle all languages and even be extended easily to other information like programming languages. It also allows us to write custom analysers and based on this we've built amazing capabilities, such as using word embedding (word2vec) to recognise what words actually mean and group / tag them accordingly.
Learning indexes
One of the most significant changes during 2016 was switching on indexes that can be updated "in place", in real-time. The main implication of this is that results can be improved constantly without creating a new index, but long term this extends much further.
Search indexes were created to handle deficiencies when running text based queries against databases. In order to improve the retrieval quality, logic was added to parse, interpret and score unstructured text before storing it in ways more favourable for text queries. For fast query speed and higher compression on disk, data was written to immutable structures (unchanging) so they could be read without any write locking (databases prevent reads during data updates). Fast forward ~20 years and this is still the fundamental approach to search indexes, in fact most search today is still powered by code originating in the late 90s.
The downsides of immutable indexes:
- Freshness - the world is now more real-time, bad and outdated results are not tolerated like they used to be.
- Performance - merging and compacting indexes is brutal from a resource perspective, imagine every time you edited a paragraph in a book you had to throw the book out and print the entire book again!
- Scoring - the relationship between queries and results becomes more obvious over time, it would be useful to make scoring updates without needing to write an entirely new index.
There has been some serious effort over the last few years to address the freshness issue, mostly by hiding it. People even sell products based on Lucene as being "real-time" and "databases", which is amusing. Lucene is a great product, but it was never designed for high update frequency, people who try it wonder why it uses so much CPU and IO, but it's obvious once the underlying structure is understood.
Scoring is another area people are trying to improve. Learn to rank techniques are becoming more prominent, performance is finally being looped back into the ranking algorithm, but for very unstructured information, many results can still have tied ranking scores, particularly for very short queries against very large data sets. Index scores (for term-document intersections) are normally set using statistical distributions across the whole collection of documents, which completely ignores a) the context in which the term was used and b) how it has performed previously for that particular query. It is highly useful to make these scores variable based on performance and machine learning models, which is what we've done. This allows us to update the importance of a result for each individual query without writing new indexes, which opens up a whole new world of experimentation and ranking performance optimisation.
This allows us to update the importance of a result for each individual query without writing new indexes.
Pipelines
Pipelines are templates for running complicated data processing and ranking models when adding records or querying. From an end user perspective this provides a very simple API interface for integration.
Breaking everything into many smaller pieces is great for us to develop and test, but we found it produced an API that was just too complex. For example a search may or may not be autocompleted, boosted in a variety of ways, have synonyms added, be classified, or clustered, or many other things. Most end users want their problem solved and largely don't care or have the time to work it out, so we've worked hard to create a new approach.
The same goes for processing records. We don't just allow records to be added as is, they can be transformed to modify or create new information, or power other features, such as autocomplete (e.g. a product title may be used to train the autocomplete service). We also allow classification models to create new fields automatically categorising the record and much more. This type of templating is pluggable and will allow us to add almost any data processing step into query or record processing pipelines.
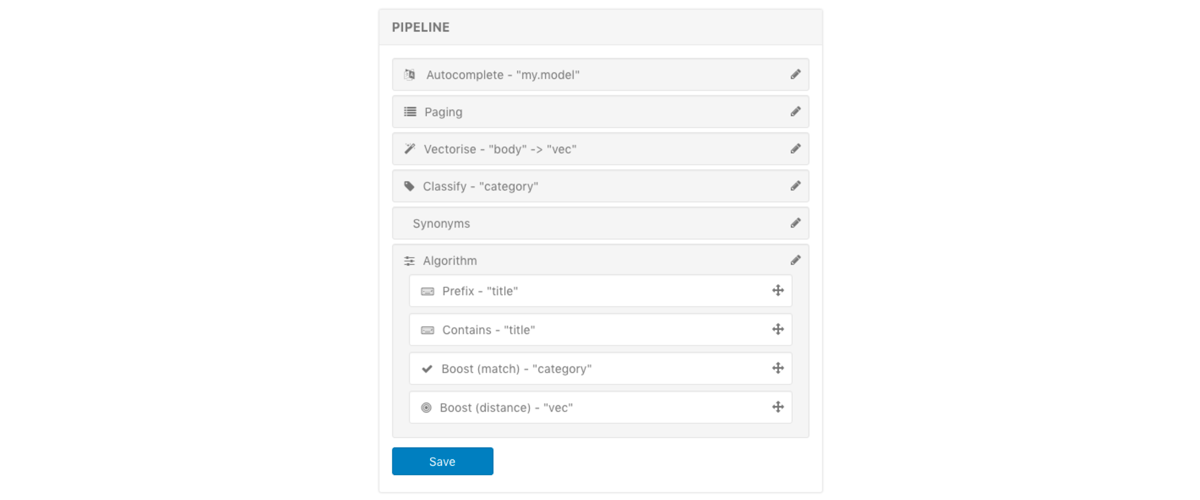
By labelling pipelines we can provide an extremely simple external interface that hides a powerful series of data processing steps (query understanding) and algorithm prioritisation. Secondly the labels provide an easy way to run analytics and machine learning optimisations to validate how each piece impacts search performance.
Summary
2016 was an amazing year for our technical team. We now have extremely low latency search infrastructure, result rankings are optimising themselves in realtime, we have improved availability and scalability, simpler integrations, more SDKs, better data processing and much more...


